基本渲染原理
关于屏幕显示图像的原理,有很多优秀的文章都介绍过了,这里就不重复介绍了。可以查看下面的链接:
iOS保持界面流畅的技巧——讲述了渲染的基本原理也有很多列表优化的方式。
iOS 渲染架构
在 WWDC 的 Advanced Graphics and Animations for iOS Apps(WWDC14 419,关于 UIKit 和 Core Animation 基础的session 在早年的 WWDC 中比较多)中有这样一张图:

整个流水线一共有下面几个步骤:
- Handle Events
这个过程中会先处理点击事件,这个过程中有可能会需要改变页面的布局和界面层次。
- Commit Transaction
此时 app 会通过 CPU 处理显示内容的前置计算,比如布局计算、图片解码等任务,接下来会进行详细的讲解。之后将计算好的图层进行打包发给 Render Server。
- Decode
打包好的图层被传输到 Render Server 之后,首先会进行解码。注意完成解码之后需要等待下一个 RunLoop 才会执行下一步 Draw Calls。
- Draw Calls
解码完成后,Core Animation 会调用下层渲染框架(比如 OpenGL 或者 Metal)的方法进行绘制,进而调用到 GPU。
- Render
这一阶段主要由 GPU 进行渲染。
- Display
显示阶段,需要等 render 结束的下一个 RunLoop 触发显示。
Commit Transaction 做了什么?
一般开发当中能影响到的就是 Handle Events 和 Commit Transaction 这两个阶段,这也是开发者接触最多的部分。Handle Events 就是处理触摸事件,而 Commit Transaction 这部分中主要进行的是:Layout、Display、Prepare、Commit 等四个具体的操作。
- Layout:构建视图
这个阶段主要处理视图的构建和布局,具体步骤包括:
- 调用重载的 layoutSubviews 方法
- 创建视图,并通过 addSubview 方法添加子视图
- 计算视图布局,即所有的 Layout Constraint
由于这个阶段是在 CPU 中进行,通常是 CPU 限制或者 IO 限制,所以我们应该尽量高效轻量地操作,减少这部分的时间,比如减少非必要的视图创建、简化布局计算、减少视图层级等。
- Display:绘制视图
这个阶段主要是交给 Core Graphics 进行视图的绘制,注意不是真正的显示,而是得到前文所说的图元 primitives 数据:
注意正常情况下 Display 阶段只会得到图元 primitives 信息,而位图 bitmap 是在 GPU 中根据图元信息绘制得到的。但是如果重写了 drawRect: 方法,这个方法会直接调用 Core Graphics 绘制方法得到 bitmap 数据,同时系统会额外申请一块内存,用于暂存绘制好的 bitmap。
由于重写了 drawRect: 方法,导致绘制过程从 GPU 转移到了 CPU,这就导致了一定的效率损失。与此同时,这个过程会额外使用 CPU 和内存,因此需要高效绘制,否则容易造成 CPU 卡顿或者内存爆炸。
- Prepare:Core Animation 额外的工作
这一步主要是:图片解码和转换
- Commit:打包并发送
这一步主要是:图层打包并发送到 Render Server。
注意 commit 操作是依赖图层树递归执行的,所以如果图层树过于复杂,commit 的开销就会很大。这也是我们希望减少视图层级,从而降低图层树复杂度的原因。
离屏渲染
如果要在显示屏上显示内容,我们至少需要一块与屏幕像素数据量一样大的 frame buffer,作为像素数据存储区域,而这也是 GPU 存储渲染结果的地方。如果有时因为面临一些限制,无法把渲染结果直接写入 frame buffer,而是先暂存在另外的内存区域,之后再写入f rame buffer,那么这个过程被称之为离屏渲染。
离屏渲染的过程
通常的渲染流程是这样的:

App 通过 CPU 和 GPU 的合作,不停地将内容渲染完成放入 Framebuffer 帧缓冲器中,而显示屏幕不断地从 Framebuffer 中获取内容,显示实时的内容。
而离屏渲染的流程是这样的:

与普通情况下 GPU 直接将渲染好的内容放入 Framebuffer 中不同,需要先额外创建离屏渲染缓冲区 Offscreen Buffer,将提前渲染好的内容放入其中,等到合适的时机再将 Offscreen Buffer 中的内容进一步叠加、渲染,完成后将结果切换到 Framebuffer 中。
离屏渲染的效率问题
GPU 的操作是高度流水线化的。本来所有计算工作都在有条不紊地正在向 frame buffer输出,此时突然收到指令,需要输出到另一块内存,那么流水线中正在进行的一切都不得不被丢弃,切换到只能服务于我们当前的“切圆角”操作。等到完成以后再次清空,再回到向 frame buffer 输出的正常流程。Offscreen Buffer 和 Framebuffer 进行内容切换的代价也非常大。
并且 Offscreen Buffer 本身就需要额外的空间,大量的离屏渲染可能早能内存的过大压力。与此同时,Offscreen Buffer 的总大小也有限,不能超过屏幕总像素的 2.5 倍。
可见离屏渲染的开销非常大,一旦需要离屏渲染的内容过多,例如在 tableView 或者 collectionView 中,滚动的每一帧变化都会触发每个 cell 的重新绘制,因此一旦存在离屏渲染,上面提到的上下文切换就会每秒发生60次。这就很可能造成 App 的界面卡顿,掉帧情况的出现。所以,大部分情况下我们应该避免离屏渲染的出现。
为什么会离屏渲染
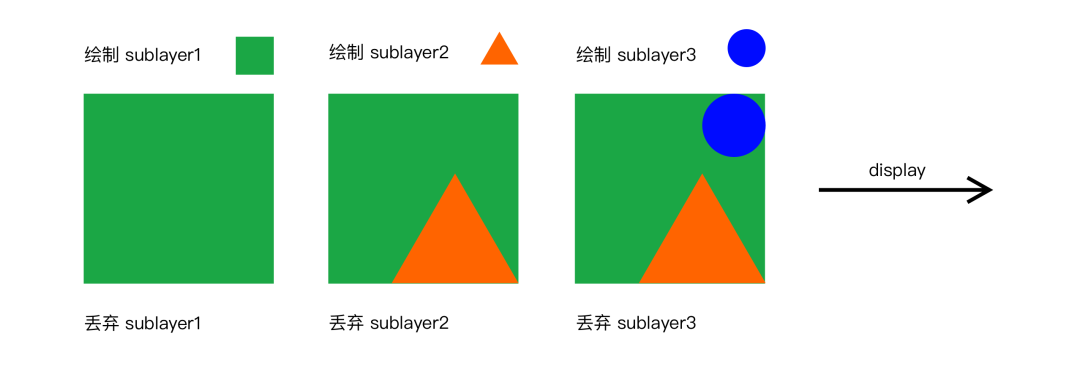
在上面的渲染流水线示意图中我们可以看到,主要的渲染操作都是由 CoreAnimation 的 Render Server 模块,通过调用显卡驱动所提供的 OpenGL/Metal 接口来执行的。Render Server 会遵循“画家算法”,在这种算法下会按层绘制,首先绘制距离较远的场景,然后用绘制距离较近的场景覆盖较远的部分。
在普通的 layer 绘制中,上层的 sublayer 会覆盖下层的 sublayer,下层 sublayer 绘制完之后就可以抛弃了,从而节约空间提高效率。所有 sublayer 依次绘制完毕之后,整个绘制过程完成,就可以进行后续的呈现了。

举例:
- 不设置裁剪和圆角
- 设置了裁剪和圆角

看完了上面两个对比示例,我们再来看看 layer 的内容层级:

view.layer.cornerRadius 代码只会默认设置 backgroundColor 和 border 的圆角,而不会设置 content 的圆角,除非同时设置了 layer.masksToBounds 为 true(对应 UIView 的 clipsToBounds 属性)。如果只是设置了 cornerRadius 而没有设置 masksToBounds,由于不需要叠加裁剪,此时是并不会触发离屏渲染的。而当设置了裁剪属性的时候,由于 masksToBounds 会对 layer 以及所有 subLayer 的 content 都进行裁剪,所以不得不触发离屏渲染。
为什么需要使用离屏渲染
知道了离屏渲染的逻辑之后,我们可以知道离屏渲染产生的其中一个原因了:
- 一些特殊效果需要使用额外的 Offscreen Buffer 来保存渲染的中间状态,所以不得不使用离屏渲染。—— 系统自动触发
另一种情况是:
- 处于效率目的,可以将内容提前渲染保存在 Offscreen Buffer 中,达到复用的目的。—— 系统主动触发
离屏渲染场景
根据上面为什么要使用离屏渲染的两个原因,针对两种情况,列出常见的离屏渲染场景。
- 系统自动触发——不得不使用(应尽量避免的)
- 使用了 mask 的 layer (layer.mask)
- 需要进行裁剪的 layer (layer.masksToBounds / view.clipsToBounds)
- 设置了组透明度为 YES,并且透明度不为 1 的 layer (layer.allowsGroupOpacity/layer.opacity)
- 添加了投影的 layer (layer.shadow*)
- 绘制了文字的 layer (UILabel, CATextLayer, Core Text 等)
- UIBlurEffect
其他还有一些,类似 allowsEdgeAntialiasing(抗锯齿)等等也可能会触发离屏渲染,原理也都是类似:如果你无法仅仅使用 frame buffer 来画出最终结果,那就只能另开一块内存空间来储存中间结果。
- 系统主动触发——处于效率目的
- 采用了光栅化的 layer (layer.shouldRasterize)
shouldRasterize 光栅化
开启光栅化后,会触发离屏渲染,Render Server 会强制将 CALayer 的渲染位图结果 bitmap 保存下来,这样下次再需要渲染时就可以直接复用,从而提高效率。
而保存的 bitmap 包含 layer 的 subLayer、圆角、阴影、组透明度 group opacity 等,所以如果 layer 的构成包含上述几种元素,结构复杂且需要反复利用,那么就可以考虑打开光栅化。
圆角、阴影、组透明度等会由系统自动触发离屏渲染,那么打开光栅化可以节约第二次及以后的渲染时间。而多层 subLayer 的情况由于不会自动触发离屏渲染,所以相比之下会多花费第一次离屏渲染的时间,但是可以节约后续的重复渲染的开销。
不过使用光栅化的时候需要注意以下几点:
- 如果 layer 不能被复用,则没有必要打开光栅化。
- 如果 layer 不是静态,需要被频繁修改,比如处于动画之中,那么开启离屏渲染反而影响效率。
- 离屏渲染缓存内容有时间限制,缓存内容 100ms 内如果没有被使用,那么就会被丢弃,无法进行复用。
- 离屏渲染缓存空间有限,超过 2.5 倍屏幕像素大小的话也会失效,无法复用。
特殊的离屏渲染——CPU离屏渲染
大家知道,如果我们在 UIView 中实现了 drawRect 方法,就算它的函数体内部实际没有代码,系统也会为这个 view 申请一块内存区域,等待 CoreGraphics 可能的绘画操作。
对于类似这种“新开一块 CGContext 来画图“的操作,有很多文章和视频也称之为“离屏渲染”(因为像素数据是暂时存入了CGContext,而不是直接到了frame buffer)。进一步来说,其实所有 CPU 进行的光栅化操作(如文字渲染、图片解码),都无法直接绘制到由 GPU 掌管的 frame buffer,只能暂时先放在另一块内存之中,说起来都属于“离屏渲染”。
自然我们会认为,因为 CPU 不擅长做这件事,所以我们需要尽量避免它,就误以为这就是需要避免离屏渲染的原因。但是根据苹果工程师的说法,CPU 渲染并非真正意义上的离屏渲染。另一个证据是,如果你的 view 实现了 drawRect,此时打开 Xcode 调试的“Color offscreen rendered yellow”开关,你会发现这片区域不会被标记为黄色,说明 Xcode 并不认为这属于离屏渲染。
其实通过 CPU 渲染就是俗称的“软件渲染”,而真正的离屏渲染发生在 GPU。
离屏渲染的优化手段
圆角优化
- 对于图片的圆角,统一采用“precomposite”的策略,也就是不经由容器来做剪切,而是预先使用 CoreGraphics 为图片裁剪圆角。
- 对视视频的圆角,实时裁剪性能会耗费比较严重,直接添加四个白色弧形的 layer,仿造出圆角效果。
- 对于视图,如果保证切除圆角位置没有需要裁剪的子元素,可以直接设置 layer.backgroundColor 并直接设置cornerRadius。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
| // MARK : 为 UIImage 绘制圆角
- (UIImage *)jt_imageByRoundCornerRadius:(CGFloat)radius
corners:(UIRectCorner)corners
borderWidth:(CGFloat)borderWidth
borderColor:(UIColor *)borderColor
borderLineJoin:(CGLineJoin)borderLineJoin {
if (corners != UIRectCornerAllCorners) {
UIRectCorner tmp = 0;
if (corners & UIRectCornerTopLeft) tmp |= UIRectCornerBottomLeft;
if (corners & UIRectCornerTopRight) tmp |= UIRectCornerBottomRight;
if (corners & UIRectCornerBottomLeft) tmp |= UIRectCornerTopLeft;
if (corners & UIRectCornerBottomRight) tmp |= UIRectCornerTopRight;
corners = tmp;
}
UIGraphicsBeginImageContextWithOptions(self.size, NO, self.scale);
CGContextRef context = UIGraphicsGetCurrentContext();
CGRect rect = CGRectMake(0, 0, self.size.width, self.size.height);
CGContextScaleCTM(context, 1, -1);
CGContextTranslateCTM(context, 0, -rect.size.height);
CGFloat minSize = MIN(self.size.width, self.size.height);
if (borderWidth < minSize / 2) {
UIBezierPath *path = [UIBezierPath bezierPathWithRoundedRect:CGRectInset(rect, borderWidth, borderWidth) byRoundingCorners:corners cornerRadii:CGSizeMake(radius, borderWidth)];
[path closePath];
CGContextSaveGState(context);
[path addClip];
CGContextDrawImage(context, rect, self.CGImage);
CGContextRestoreGState(context);
}
if (borderColor && borderWidth < minSize / 2 && borderWidth > 0) {
CGFloat strokeInset = (floor(borderWidth * self.scale) + 0.5) / self.scale;
CGRect strokeRect = CGRectInset(rect, strokeInset, strokeInset);
CGFloat strokeRadius = radius > self.scale / 2 ? radius - self.scale / 2 : 0;
UIBezierPath *path = [UIBezierPath bezierPathWithRoundedRect:strokeRect byRoundingCorners:corners cornerRadii:CGSizeMake(strokeRadius, borderWidth)];
[path closePath];
path.lineWidth = borderWidth;
path.lineJoinStyle = borderLineJoin;
[borderColor setStroke];
[path stroke];
}
UIImage *image = UIGraphicsGetImageFromCurrentImageContext();
UIGraphicsEndImageContext();
return image;
}
|
SDWebImage 加载网络图片时,可以利用 SDImageRoundCornerTransformer 为图片直接绘制圆角。
阴影优化
- 阴影的设置都通过 shadowPath 指定阴影路径。
其它情况
- 特除形状的 view,使用 layer mask 并打开 shouldRasterize 来对渲染结果进行缓存。
卡顿监控
FPS
可以通过 CADisplayLink 的机制来计算出实时的帧率,但是这个只是可以看出 CPU 的卡顿,而对于 GPU 的卡顿就无法检测了。所以说,在精准的界面检测中 FPS 只能作为参考来评测界面卡顿。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
| @interface JTFPSMonitor : NSObject
/**
FPS 监控回调
*/
@property (nonatomic, copy) void(^fpsCallback)(float fps);
@end
@implementation JTFPSMonitor {
CADisplayLink *_link;
NSUInteger _count;
NSTimeInterval _lastTime;
}
- (instancetype)init {
self = [super init];
if (self) {
_link = [CADisplayLink displayLinkWithTarget:self selector:@selector(tick:)];
[_link addToRunLoop:[NSRunLoop mainRunLoop] forMode:NSRunLoopCommonModes];
}
return self;
}
- (void)dealloc {
[_link invalidate];
}
- (void)tick:(CADisplayLink *)link {
if (_lastTime == 0) {
_lastTime = link.timestamp;
return;
}
_count++;
NSTimeInterval delta = link.timestamp - _lastTime;
if (delta < 1) {
return;
}
_lastTime = link.timestamp;
float fps = _count / delta;
if (self.fpsCallback) {
self.fpsCallback(fps);
}
_count = 0;
}
@end
|
Runloop
代码量不大,全文抄录。相关说明也都在注释里面。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
| @interface JTStuckMonitor () {
CFRunLoopObserverRef runLoopObserver;
int timeoutCount;
@public
CFRunLoopActivity runLoopActivity;
dispatch_semaphore_t dispatchSemaphore;
}
@end
@implementation JTStuckMonitor
- (void)start {
// Dispatch Semaphore保证同步
dispatchSemaphore = dispatch_semaphore_create(0);
// 创建一个观察者
CFRunLoopObserverContext context = {0, (__bridge void *)self, NULL, NULL};
runLoopObserver = CFRunLoopObserverCreate(kCFAllocatorDefault,
kCFRunLoopAllActivities,
YES,
0,
&runloopObserverCallBack,
&context);
//将观察者添加到主线程runloop的common模式下的观察中
CFRunLoopAddObserver(CFRunLoopGetMain(), runLoopObserver, kCFRunLoopCommonModes);
// 创建子线程监控
dispatch_async(dispatch_get_global_queue(0, 0), ^{
//子线程开启一个持续的loop用来进行监控
while (YES) {
// 假定连续5次超时50ms认为卡顿(当然也包含了单次超时250ms)
long semaphoreWait = dispatch_semaphore_wait(self->dispatchSemaphore, dispatch_time(DISPATCH_TIME_NOW, 50*NSEC_PER_MSEC));
if (semaphoreWait != 0) {
if (!self->runLoopObserver) {
self->timeoutCount = 0;
self->dispatchSemaphore = 0;
self->runLoopActivity = 0;
return;
}
//两个runloop的状态,BeforeSources 和 AfterWaiting 这两个状态区间时间能够检测到是否卡顿
if (self->runLoopActivity == kCFRunLoopBeforeSources || self->runLoopActivity == kCFRunLoopAfterWaiting) {
if (++self->timeoutCount < 5) {
continue;
}
// 检测到卡顿,抓取堆栈信息
}
}
self->timeoutCount = 0;
}
});
}
/*
如果 RunLoop 的线程,进入睡眠前方法的执行时间过长而导致无法进入睡眠,或者线程唤醒后接收消息时间过长而无法进入下一步的话,就可以认为是线程受阻了。如果这个线程是主线程的话,表现出来的就是出现了卡顿。
所以,如果我们要利用 RunLoop 原理来监控卡顿的话,就是要关注这两个阶段。RunLoop 在进入睡眠之前和唤醒后的两个 loop 状态定义的值,分别是 kCFRunLoopBeforeSources 和 kCFRunLoopAfterWaiting ,也就是要触发 Source0 回调和接收 mach_port 消息两个状态。
*/
static void runloopObserverCallBack(CFRunLoopObserverRef observer,
CFRunLoopActivity activity,
void *info) {
JTStuckMonitor *stuckMonitor = (__bridge JTStuckMonitor *)info;
stuckMonitor->runLoopActivity = activity;
/*
kCFRunLoopEntry = (1UL << 0),
kCFRunLoopBeforeTimers = (1UL << 1),
kCFRunLoopBeforeSources = (1UL << 2),
kCFRunLoopBeforeWaiting = (1UL << 5),
kCFRunLoopAfterWaiting = (1UL << 6),
kCFRunLoopExit = (1UL << 7),
kCFRunLoopAllActivities =
*/
switch (activity) {
case kCFRunLoopEntry:
NSLog(@"------- kCFRunLoopEntry 进入 loop-------");
break;
case kCFRunLoopBeforeTimers:
NSLog(@"------- kCFRunLoopBeforeTimers 触发 Timer 回调 -------");
break;
case kCFRunLoopBeforeSources:
NSLog(@"------- kCFRunLoopBeforeSources 触发 Source0 回调 -------");
break;
case kCFRunLoopBeforeWaiting:
NSLog(@"------- kCFRunLoopBeforeWaiting 等待 mach_port 消息 -------");
break;
case kCFRunLoopAfterWaiting:
NSLog(@"------- kCFRunLoopAfterWaiting 接收 mach_port 消息 -------");
break;
case kCFRunLoopExit:
NSLog(@"------- kCFRunLoopExit 退出 loop -------");
break;
default:
break;
}
dispatch_semaphore_t semaphore = stuckMonitor->dispatchSemaphore;
dispatch_semaphore_signal(semaphore);
}
- (void)end {
if (!runLoopObserver) {
return;
}
CFRunLoopRemoveObserver(CFRunLoopGetMain(), runLoopObserver, kCFRunLoopCommonModes);
CFRelease(runLoopObserver);
runLoopObserver = NULL;
}
@end
|